
CCP Yukai explains why server updates are nessisary in todays age.
As CCP we have always chosen the more challenging path in how we design games; one world-wide single shard server proves that. As we’ve grown and the number of logins has risen we’ve gone through iterations in fighting lag. The War on Lag is never ending, because EVE Online is always growing. But we have some interesting things to show you this week. This is the third in a series of three blogs that will show you how we fight lag through hardware upgrades, software fixes, and even wrestling the internet itself…
One day we woke up and our super cool database servers… well… weren’t super cool anymore.
128GB of RAM seems to be available on laptops now…
Plain old SSD’s… My mom has one…
4Gb/s storage networking… I can do that with some bubble gum, two paper clips, and a bit of twine now…
So how do you take “old cool” to “new cool” in the technology world? You multiply by 4!
After some months of internal debate about what the next generation of Tranquility’s (TQ) database hardware should look like, we decided to upgrade every aspect of our systems, leaving no trace of the old environment.
Step one: (Upgrade the Storage Network)
Previously, the servers were connected to storage via 2 x 4Gb/s fiberchannel connections. We have upgraded to a more future proof connection of 4 x 8Gb/s fiberchannel links. With these links bonded together not only do we get added redundancy but the ability to push more traffic than ever for things like backups and data collection without encroaching on the bandwidth reserved for players.
We didn’t want to have to worry about using Frankenstein parts or old switches that needed updating, so even the fiberchannel switches themselves are brand new and dedicated to TQ. In the long term, other services that need access to the TQ storage array will have a separate switch with both software and hardware limited traffic capabilities to protect the cluster.
WIN: 8Gb/s to 32Gb/s and no sharing 😉
Step two: (Upgrade the RAM)
Databases like RAM. Probably one of the most significant performance increases is in the amount of buffer cache we can allow SQL Server to have. This increases the average lifetime of data in cache. Our old systems were on 128GB of DDR2 RAM. This sounds really awesome and while were considered not going to extremes with the RAM… we did. The new system is running 512GB of DDR3 (low latency) memory!
We noticed immediate performance increases in the Buffer Cache Hit Ratio, which is a counter indicating how often the server goes to the buffer (fast) instead of disks (not as fast). The old TQ database was at 97% while the New TQ database is at 99.7%. (We don’t need no stinkin disks!)
WIN: 128GB of DDR2 to 512GB of DDR3, 111GB of DB Cache to 460 DB Cache and it all takes our Page Life Expectancy (the time data stays in RAM) from 7.9 mins to 2.8 hours!
(all that RAM in this tiny little box)
Step three: (Upgrade the CPU)
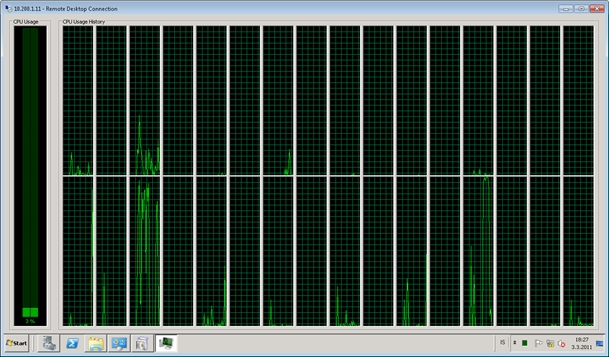
If you are going to upgrade everything else, it makes sense to add some better CPU’s. Now we already had Intel’s X7460‘s @ 2.66GHz and they run well but gave us issues because there was no hyper-threading capabilities and our database server needed more threads. Luckily the new X7560‘s @2.26GHz gave us 2 more cores per chip and allowed us to turn on hyper-threading for the database server!
One example of the performance change is the backup process previously brought the CPU utilization to 90% of TQ’s CPU capacity. Today we have that down to just under 55%!
Before you get too caught up in the clock cycles going from 2.66GHz down to 2.26GHz… take a look at what changes were made in the architecture. (Intel Site) It’s really too much to post here but the performance increase for DB servers is staggering.
WIN: 12 to 32 logical processors plus a bonus for the new architecture gain over the old processor in our test and in lab tests. Plus, seriously… that screen shot by its self makes the server 400% faster.
(now that is some sexy stuff)
(CPU before)
(CPU after)
Step four: (Upgrade the Storage)
Our previous system was fast (we really love the RamSan 500’s… they are sexy and will get reused) but it was limited in size, scalability, and features that let us protect the database. At 2TB of RAID protected SSD’s we were hard pressed to find a single solution any better… So we went out and found two! We installed two of the V7000 StoreWise systems from IBM. With not only 18 drives of high performance SSD’s, but also another 72 drives of 15K RPM SAS drives as well.
For the first time we have the ability to migrate data to the appropriate disk arrays and have space to allow for more live data to be stored and retained on or near the production system. Our previous systems were tested at about 55K IOPS at a 2.9Gb/s Average Transfer Rate. We have tested our new system to over 100K IOPS and over 10Gb/s Average Transfer Rate already.
Another example of how much of an impact the new storage system is having on performance is the change in Disk Queue Length (I/O Requests). We went from 4.5 to just 3.0! This might not sound like a very big deal when your PC at home is doing 100 IOPS… but at a system doing 50K+ IOPS 33% reduction in Disk Queue Length is massive.
WIN: Transfer speed from 2.9Gb/s to 10Gb/s tested. Total storage capacity on SSD’s doubled. Aggregate storage on all production capable tiers increased from 2TB non redundant to 11.5TB and 1 for 1 redundant hardware.
(we have 4 of these now)
(disk I/O before)
(disk I/O after)
Extras:
No single point of failure in the cluster!
Side to side asynchronous mirroring option!
SNAP mirroring for point in time recovery!
More backups stored!
Thin Provisioning!
Expandable to 240 Drive! MUHWAWAWAWA
We have also seen another positive, albeit unplanned, side effect of the increased performance of the new database systems. Previously if our SQL Server cluster needed to fail over to the redundant server, every node in the cluster died and all players were disconnected.
(complete loss of nodes and sessions)
We recently failed over to our secondary database server on the new system and only 3 nodes out of 208 died! This means with some tweaks we may be able to fail the servers, storage, and switching environment without a single disconnect!
(only a few nodes lost)
The software teams are already looking into this and a lot of other opportunities presented with this kind of serious DB horsepower.
Some hardware specs: (AKA Tech Porn)
Each server has:
2 x 8 Core Intel x7560 processors at 2.26GHz
32 x 16GB strips of RAM for a total of 512GB DDR3 RAM
4 x Gigabit Ethernet cards
2 x Dual-port 8Gb/s Fiberchannel cards
4 x 15K 300GB SAS drives internal
9 x 300 GB SSD’s drives RAID 5 attached via IBM V7000
36 x 600 GB SAS drives RAID 10 attached via IBM V7000
The whole system has:
Over 1TB of RAM
64 logical processors (w/ hyper-threading enabled)
32Gb/s of storage throughput capacity
200,000 IOPS capacity
51TB of RAW storage capacity (23TB after RAID and spares)
And it fits in my pocket
Some cool I/O test results!
Backup
Server —- Disk System —- Time —- Speed
Old TQ DB —- Current (30) FC Disks —- 73 mins —- 2.8 Gb/s
New TQ DB —- Current (30) FC Disks —- 60 mins —- 3.2 Gb/s
New TQ DB —- New (34) SAS Disks —- 23 mins —- 8.5 Gb/s
Restore
Server —- Disk System —- Time
Old TQ DB —- Current (30) FC Disks —- 180 mins
New TQ DB —- Current (30) FC Disks —- 66 mins
New TQ DB —- New (34) SAS Disks —- 59 mins
* Note: for you SQL Server geeks out there… our backups are HIGHLY tweaked. Additions we made to the configs below
Writing to 8 files on 4 logical drives (LUNs) (example: D:1&2, E:3&4, F:5&6, G:7&8)
BUFFERCOUNT = 2200
BLOCKSIZE = 65536
MAXTRANSFERSIZE=2097152
This took us from maxing out at 3.3Gb/s average transfer rate to being able to get as high as 8.8Gb/s average transfer rate and instantaneous peaks of over 14Gb/s. It changed our backup times even on the new system from 60 min to 22 min backups on this tweak! Please don’t create a petition when you break your own SQL Server trying this. Unless you have our exact setup, 512GB of RAM, and the DBA team we do… it will likely NOT work with these settings for you. But, if you wanted to do what we did… well that’s why I put it there.
In summary, the new database hardware will help make sure the single universe of EVE is able to keep up with the new release, growth of the player base, and the need for improved backup and restoration.
Big shoutout to CCP Valar and CCP Denormalized who made this blog possible.
Fly Dangerous!
CCP Yokai
P.S. This blog has graphs








Recent Comments